中国科学技术大学精准智能化学重点实验室商红慧教授、杨金龙教授团队与中国科学院计算技术研究所刘颖高级工程师,华东师范大学何晓教授等团队合作完成的研究成果“Pushing the Limit of Quantum Mechanical Simulation to the Raman Spectra of a Biological System with 100 Million Atoms”[1]成功入围2024年戈登·贝尔奖[2],这是2024年入围该奖的唯一中国团队成果,也是该团队继2021年后再次入围该奖项。戈登·贝尔奖是国际高性能计算应用领域最高奖,由美国计算机协会(ACM)颁发,用于表彰世界范围内高性能计算的杰出成就,尤其是高性能计算应用于科学、工程和大规模数据分析领域的创新工作,被称为“超算领域的诺贝尔奖”。此前,该成果也获得了2024年中国计算机学会(CCF) “中国超算年度最佳应用奖”。
|
|
| 入围ACM Gorden Bell奖 | 获得“中国超算年度最佳应用奖” |


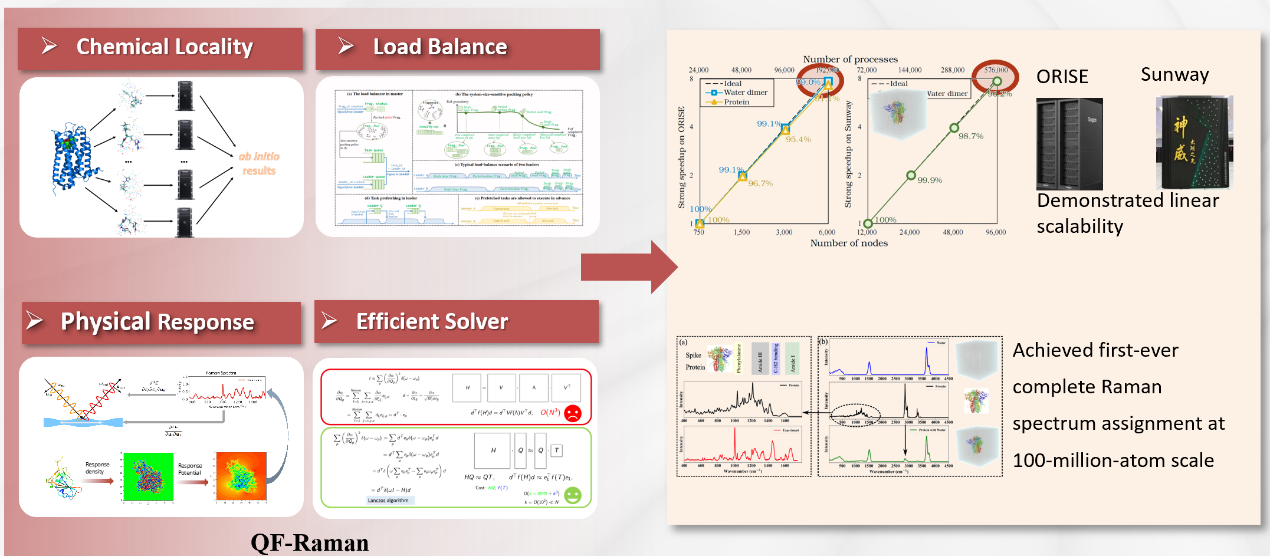
拉曼光谱是研究生物分子结构的重要工具,被广泛应用于药物开发、疾病诊断等领域,然而,拉曼光谱量子模拟计算量巨大。此前的拉曼光谱量子模拟仅能处理数千原子的小体系,研究团队开发的QF-RAMAN程序突破了这一限制,首次实现了包含1亿多原子的新冠病毒刺突蛋白在水溶液中的拉曼光谱量子模拟,与以往工作相比取得了4~5个数量级的提升。这一突破的实现得益于团队在算法设计和工程技术方面的多项创新。在传统密度泛函理论(DFT)和密度泛函微扰理论(DFPT)计算中,计算量随体系规模的增大呈现三次方增长,这使得计算通常只能局限于小型体系。针对以上问题,团队开发了将全电子全势密度泛函微扰理论与量子分块算法深度融合的新方法,将复杂生物分子分解为多个子系统,显著降低了计算复杂度。同时团队针对海量分块计算的负载均衡难题,开发了分块体量敏感的多级调度技术,提高了海量分块计算的并行可扩展性;针对小规模运算的异构加速难题,设计了弹性任务卸载技术,通过小规模运算的灵活聚合,大幅提高异构加速器的硬件利用率。此外,QF-RAMAN程序采用OpenCL通用异构并行计算框架,能在不同硬件架构(CPU、GPU、SW等)的超级计算机上,借助OpenCL编译工具链(oneAPI、rocm、swcl等)实现跨平台运行。在最新一代神威超级计算机上,该程序利用96,000个计算节点(超过3,700万个计算核心)实现了399.9 PFLOP/s的双精度峰值性能;在东方超级计算机上,使用6,000个节点(24,000个GPU),程序也展现了85 PFLOP/s的优异性能。在新一代神威超级计算机上取得了99%的弱可扩展性测试结果,充分展示了该方法的高效性和可扩展性。在此基础上,团队提出了适用于亿级原子体系的矩阵方程求解拉曼光谱的新算法,避免了直接对角化求解,为高精度拉曼光谱计算提供了全新方案,有效解决了大规模量子力学拉曼模拟中的关键技术难题。
这项研究表明,量子力学模拟可以扩展到前所未有的规模,这也为理解复杂生物系统开辟了新途径。以新冠病毒研究为例,该方法可以精确模拟刺突蛋白的结构特征,为深入理解病毒感染机制提供了科学支撑,为药物研发和疫苗设计贡献了重要参考。这一方法还可推广到其他重要生物分子的研究中,成为生物医学研究领域强大的研究工具。此次技术突破不仅展示了中国在高性能计算和计算化学领域的领先地位,也为量子力学模拟的应用场景探索了全新的可能。这一成果为高性能计算与科学研究的深度融合奠定了坚实的技术基础,将推动生物分子模拟研究进入新阶段。
在国产超算上实现亿级原子生物分子拉曼光谱量子力学模拟
2024年顶级超级计算系统发展:
2024年国际超级计算大会(SC24)上还揭晓了最新的全球超级计算机 TOP500 榜单[3],展示了我国之外的超级计算机发展态势,前10的表单如下:
序号 | 超算名称 | 国家 | 核心配置 | 内核 | 运算性能(TFlop/s) | 峰值性能(TFlop/s) | 功率(kW) |
1 | El Capitan | 美国 | AMD MI300A APU | 11039616 | 1742.00 | 2746.38 | 29581 |
2 | Frontier | 美国 | AMD MI250X GPU | 9066176 | 1353.00 | 2055.72 | 24607 |
3 | Aurora | 美国 | Intel GPU Max | 9264128 | 1012.00 | 1980.01 | 38698 |
4 | Eagle | 美国 | NVIDIA H100 GPU | 2073600 | 561.20 | 846.84 | / |
5 | HPC6 | 意大利 | AMD MI250X GPU | 3143520 | 477.90 | 606.97 | 8461 |
6 | Supercomputer Fugaku | 日本 | A64FX 48C CPU | 7630848 | 442.01 | 537.21 | 29899 |
7 | Alps | 瑞士 | NVIDIA GH200 | 2121600 | 434.90 | 574.84 | 7124 |
8 | LUMI | 芬兰 | AMD MI250X GPU | 2752704 | 379.70 | 531.51 | 7107 |
9 | Leonardo | 意大利 | NVIDIA A100 GPU | 1824768 | 241.20 | 306.31 | 7494 |
10 | Tuolumme | 美国 | AMD MI300A APU | 1161216 | 208.10 | 288.88 | 3387 |
相关数据表明:
E级超算快速发展:迄今为止共有EI Capitan、Frontier 、Aurora 3台E级超算登榜,在2年内的时间内出现了3台,反映了应用对高性能计算的迫切需求。
芯片具备强劲算力:Top500第一的是来自美国能源部劳伦斯利弗莫尔国家实验室的新超算 EI Capitan,其基于AMD Instinct MI300A APU 的片上异构处理器,每块芯片配备有基于AMD EPYC Zen4 架构的 24 核 CPU 和基于 CDNA3 的GPGPU 加速单元,提供高达122.6 TFLOPs 的 FP64 算力和 5.3 TB/s的HBM 高速内存。
异构芯片与统一内存登台:AMD Instinct MI300A APU 通过先进封装将高性能GPU与CPU封装在一个芯片上,和 NVIDIA GH200 一样可以通过统一内存池轻松消除了传统异构系统中CPU和GPU之间数据传输的瓶颈,提高了编程便利和性能上限。
异构加速器占据主流:Top500 前十名中除了Fugaku全部采用 CPU+GPU异构模式,Top500中则有210个系统正在采用加速器/协处理器技术。GPU在浮点性能和功耗方面具备显著优势,同时具有单芯片算力大的特点,能有效减少节点数量,在目前广受青睐。能效排名Green500中前10名均由NVIDIA H100/GH200/AMD MI300A占据。但与此同时,基于 CPU 的超算系统依然具有复杂问题上的良好适用性,如Fugaku继续维持稀疏求解 HPCG 排名第一。
2024年戈登·贝尔奖其他工作:
2024年戈登·贝尔奖(Gordon Bell Prize)吸引了众多杰出的参赛作品,展示了来自全球高性能计算团队的卓越成果,旨在表彰高性能计算领域的杰出成就。戈登·贝尔奖特别强调将HPC应用于科学、工程和大规模数据分析等领域的创新工作,参赛项目通常采用最先进的技术和顶尖的超级计算平台进行计算。今年共有6项作品入围最终评奖[2],这些作品涵盖了HPC在材料科学、生物化学、蛋白质设计、基因组研究和大规模模型训练等领域的最新技术,充分展示了HPC技术的多样化前景以及应对更大规模计算挑战的创新方法。下面将介绍其他5项优秀的工作:
最终获奖:百万电子级生物分子尺度的MP2分子动力学模拟
澳大利亚与美国的科研团队以题为“Breaking the Million-Electron and 1 EFLOP/s Barriers: Biomolecular-Scale Ab Initio Molecular Dynamics Using MP2 Potentials”的项目荣获2024年戈登·贝尔奖。
该研究通过结合量子分块方法与MP2微扰理论,将大规模分子系统划分为多个可独立计算的子单元,实现了在波函数MP2理论水平上的生物分子级从头算分子动力学(AIMD)模拟。在Hartree-Fock和MP2梯度计算中采用RI方法,通过引入辅助基函数,显著降低了MP2计算的复杂度。此外,结合现代GPU架构,进一步优化了RI技术的实现,大幅提升了计算效率。引入异步时间步长有效减少了时间步延迟,优化了计算负载平衡,解决了大规模系统中的负载不均问题。通过GEMM运行时自动调优技术,根据硬件特性动态优化矩阵乘法性能,充分利用GPU内存带宽和计算核心布局。在Frontier超级计算机上,使用最多9400个节点,团队的方法实现了59%的双精度浮点峰值性能(1006.7 PFLOP/s),突破了百万电子和双精度1 EFLOP/s的AIMD模拟瓶颈。开创了分子动力学和计算化学领域的全新篇章,为探索复杂生物化学现象提供了空前的精度和规模。
其他工作:
MProt-DPO:通过直接偏好优化突破ExaFLOPS瓶颈的多模态蛋白质设计工作流程
这项创新工作提出了一种基于可扩展的、多模态大语言模型的蛋白质设计工作流程。通过结合蛋白质序列与其生化性质的自然语言描述,训练并利用大规模语言模型(LLM)生成蛋白质序列, 计算评估所生成的序列,并利用这些序列对模型进行微调。通过直接偏好优化(Direct Preference Optimization)技术引导LLM生成更符合预期的蛋白质序列,同时通过增强的工作流程技术提高了执行效率。通过在ALPS、Aurora、Frontier、Leonardo和PDX等超级计算机上的测试,混合精度下的最大持续性能达到4.11 ExaFLOPS,峰值性能为5.57 ExaFLOPS。其实验采用了3.5B和7B参数的模型,计算了两项实际任务(1)在预定的深度突变扫描基准数据集上,优化酵母蛋白HIS7中的适应性突变,(2)通过模拟数据优化苹果酸脱氢酶的设计,降低激活能垒(从而提高催化速率),展示这一完整工作流程的科学效果、可扩展性和卓越的混合精度性能。
利用混合精度核岭回归从多变量全基因组关联研究中识别遗传风险因素
该团队开发了一种基于Cholesky的混合精度求解器来加速核岭回归(KRR)计算,应用于全基因组关联研究(GWAS)。通过以图块为中心的精度自适应矩阵运算,和基于任务的执行,该团队充分发挥了低精度GPU运算的极高性能。研究应用于来自英国生物银行的30.5万患者的全基因组关联研究,采用多变量方法来识别遗传风险因素,其出色的扩展性和极高的混合精度性能在 Alps、Frontier、Leonardo、Summit四台超算上得到了展示,其中最高在Alps达到了1.805 ExaOp/s的混合精度计算性能,成功以比最先进的纯 CPU REGENIE GWAS 软件高出五个数量级的性能求解了有史以来最大的 GWAS 队列。
使用晶圆级系统打破分子动力学时间限制
该团队开发了一种基于嵌入原子法(EAM)的分子动力学代码,利用了850,000核Cerebras Wafer-Scale Engine的超高速通信和高带宽内存。该系统在涉及铜、钨和钽原子的晶界问题上实现了完美的弱扩展性,并可以扩展至多个晶圆。与Frontier GPU超算平台相比,每秒时间步数提升了457倍,同时在单位能耗的时间步数上也有大幅提升。对于最多80万个原子的问题,其每秒时间步数明显高于Quartz和Frontier超级计算机上的LAMMPS中的EAM实现,直接促进了对长时间尺度现象的建模研究。
Democratizing AI:基于GPU超算的开源可扩展LLM训练
该团队开发了一种用于训练和微调大规模语言模型(LLMs)的可扩展、可移植的开源框架AxoNN。 作者提出了一种新颖的四维混合并行算法,并详细描述了在AxoNN中应用的多项性能优化措施,包括优化矩阵乘法核性能、将非阻塞集体通信与计算重叠以及通过性能建模选择最优配置,团队成功在Perlmutter(620.1 Petaflop/s)、Frontier(1.381 Exaflop/s)和Alps(1.423 Exaflop/s)上达到了全新的扩展性和峰值性能(BF16)。此外,研究还探讨了大型LLMs在训练过程中可能记忆训练数据的潜在风险,作者还展示了在Frontier上使用AxoNN对4050亿参数的LLM进行微调的成果。
总结、回顾与展望:
2024的Top500向我们展示了当今的超算能做多好,通过芯片设计、网络互联、基础库研发等集成电路、体系结构的软硬件结合创新,将我们带到了1.7EFLOPS的时代。而戈登·贝尔奖则向我们解答了研制超级计算机到底有什么用,能不能通过更多的机器、更强的计算通信网络来解决关键应用挑战,正如今年的若干项工作在材料科学、生物化学、蛋白质设计、基因组研究和大模型训练做出的创新突破。
我们团队关于拉曼光谱的工作也是这样的例子。拉曼光谱是研究生物分子结构的重要工具,被广泛应用于药物开发、疾病诊断等领域。然而,由于计算量巨大,此前的量子力学模拟仅能处理数千原子的小体系。研究团队开发的QF-RAMAN程序突破了这一限制,在国产新一代神威超级计算机和曙光超级计算机上,首次实现了包含1亿多原子的新冠病毒刺突蛋白在水溶液中的拉曼光谱模拟,为生命科学、材料设计等研究领域提供了新的研究视角。
这一重要突破是在团队前期开创性工作基础上的重大发展:
【2011-2018】提出了全电子全势下实空间密度泛函微扰理论(DFPT)计算方法,通过利用扰动的空间局域性特征,直接在实空间计算振动性质,避免了传统倒空间方法的插值计算,使得单次DFPT计算就能获得完整的实空间信息。在分子和周期性体系中都展现出良好的计算效率和准确性[4][5]。
【2020】在国产超算上实现百万核可扩展的全电子全势下实空间密度泛函微扰理论计算[6]。
【2021】完成了数千原子生物体系的拉曼光谱计算,第一次入围戈登·贝尔奖,是中国首个入围该奖项的第一性原理应用工作[7]。
【2022】针对DFPT中的一阶电荷势能计算,重写了全电子全势框架下的泊松方程求解器,实现了35倍的异构众核加速[8]。针对Sternheimer方程求解,采用三维矩阵分区和块密集化的数据结构设计,结合自适应数据分块、双缓冲、并行表查找转置、半精度三级任务分割等优化技术,实现了响应密度矩阵计算在超大规模并行计算中的高效执行[9]。
【2023】通过提出基于局部索引和近邻原子感知的负载均衡方案,将大规模稀疏矩阵转化为小规模稠密矩阵以降低内存消耗,并提高了局部性;采用层次化打包通信方案减少集合通信开销;结合基于OpenCL的跨平台实现、内核融合、间接访存消除和细粒度并行化等计算优化技术,实现了量子力学微扰理论在神威和GPU等异构超算上的高效执行,并成功扩展至20万原子体系的模拟[10]。
【2024】将第一性原理计算规模提升至亿级原子,创造了量子力学计算拉曼光谱的世界纪录。从2021年的数千原子到现在的亿级原子,这一跨越展现了团队原创算法的持续创新能力。该工作专注于在全电子全势精确计算框架下推进高阶量子力学物理性质的大规模模拟,为生命科学、材料设计等研究领域提供了新的研究视角。通过密度泛函微扰理论与量子分块的结合,有望进一步拓展到核磁共振谱、电声耦合等更多领域的计算,为生命科学等研究带来新的机遇[1]。
未来,团队将依托国产超算平台,继续深入开展高性能计算应用研究,致力于推动量子力学计算与超级计算的协同发展,实施创新驱动发展战略,为解决重大科学问题贡献中国智慧。
成果相关论文:
[1] Honghui Shang*, Ying Liu*, Zhikun Wu, Zhenchuan Chen, Jinfeng Liu, Meiyue Shao, Yingzhou Li, Bowen Kan, Huimin Cui, Xiaobing Feng, Yunquan Zhang, Donald G. Truhlar, Hong An, Xiao He*, and Jinlong Yang*. Pushing the limit of quantum mechanical simulation to the raman spectra of a biological system with 100 million atoms. In Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, SC '24 (GB finalist).https://dl.acm.org/doi/10.1109/SC41406.2024.00011
[2] https://sc24.supercomputing.org/2024/10/presenting-the-finalists-for-the-2024-gordon-bell-prize/
[3] https://www.top500.org/lists/top500/2024/11/highs/
[4] Honghui Shang*, Christian Carbogno, Patrick Rinke, and Matthias Scheffler. Lattice Dynamics Calculations Based on Density-Functional Perturbation Theory in Real Space. Computer Physics Communications, 215, 26 (2017).
[5] Honghui Shang, Nathaniel Raimbault, Patrick Rinke, Matthias Scheffler, Mariana Rossi*, and Christian Carbogno*. All-Electron, Real-Space Perturbation Theory for Homogeneous Electric Fields: Theory, Implementation, and Application within DFT. New Journal of Physics, 20, 073040 (2018).
[6] Honghui Shang*, Xiaohui Duan*, Fang Li*, Libo Zhang, Zhiqian Xu, Kan Liu, Haiwen Luo, Yingrui Ji, Wenxuan Zhao, Wei Xue, Li Chen, and Yunquan Zhang. Many-core acceleration of the first-principles all-electron quantum perturbation calculations. Computer Physics Communications, 267,108045 (2021).
[7] Honghui Shang*, Fang Li*, Yunquan Zhang*, Libo Zhang, You Fu, Yingxiang Gao, Yangjun Wu, Xiaohui Duan, Rongfen Lin, Xin Liu, Ying Liu, and Dexun Chen. Extreme-scale Ab Initio Quantum Raman Spectra Simulations on the Leadership HPC System in China. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis,SC '21 (GB finalist).
[8] Mingchuan Wu, Yangjun Wu, Honghui Shang*, Ying Liu*, Huimin Cui, Fang Li, Xiaohui Duan, Yunquan Zhang, and Xiaobing Feng. Scaling Poisson Solvers on Many Cores via MMEwald. IEEE Transactions on Parallel and Distributed Systems, 33,1888 (2022).
[9] Xin Chen, Yingxiang Gao, Honghui Shang*, Fang Li*, Zhiqian Xu, Xin Liu, and Dexun Chen. Increasing the Efficiency of Massively Parallel Sparse Matrix-Matrix Multiplication in First-Principles Calculation on the New-Generation Sunway Supercomputer. IEEE Transactions on Parallel and Distributed Systems, 33,4752, (2022).
[10] Zhikun Wu, Yangjun Wu, Ying Liu*, Honghui Shang*, Yingxiang Gao, Zhongcheng Zhang, Yuyang Zhang, Yingchi Long, Xiaobing Feng, and Huimin Cui. Portable and scalable all-electron quantum perturbation simulations on exascale supercomputers. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC '23
(精准智能化学重点实验室、科研部)